- Amit Mirgal
- Posts
- DeepSeek V3: A New Step for AI
DeepSeek V3: A New Step for AI
DeepSeek-V3: A Powerful, Cost-Effective, and Open-Source Language Model
Amit Mirgal
January 28, 2025
We’re now a family of 416(few subscribers dropped from the last count) readers! 🎉 Thank you for being here ❤️
This newsletter is free, and I rely on your support to grow. If you enjoy it, please share it on social media or forward it to a friend — it means the world to me!
If this was forwarded to you, join us here, and if you’re starting your own newsletter, check out Beehiiv here.
If you’d like to promote your product to this network, send me an email. I’d be happy to feature your product as a short section.
Thank you for being part of this journey! 🚀
Introduction
Hey everyone! Exciting news in the world of AI – DeepSeek-V3 is here! This is a new language model that's making big waves, and we're here to break it down for you in a way that's easy to understand. Think of it as a really smart computer brain that’s getting better at understanding and using language
What is DeepSeek-V3?
DeepSeek-V3 is a large language model with a huge number of parameters, 671 billion in total, with 37 billion activated for each token
This statement highlights the sheer size and complexity of the model. The term "parameters" refers to the variables that the model learns during training, and they determine the model's ability to perform tasks
Having 671 billion total parameters makes DeepSeek-V3 a very large model, which typically means it can process more complex information and learn more intricate patterns
The fact that only 37 billion parameters are activated for each token is important. This means that while the model is very large, it doesn't use all of its parameters at once for a single task. This efficient use of parameters is related to its Mixture-of-Experts architecture.
This is a key distinction in the model's design, as it demonstrates how DeepSeek-V3 balances size and efficiency
It uses a special setup called Mixture-of-Experts (MoE), which helps it learn faster and work more efficiently
Mixture-of-Experts (MoE) is an architectural design where the model is divided into multiple specialized sub-networks, called "experts"
During processing, only a subset of these experts are activated for each input
This selective activation is the key to both learning and working efficiently. Instead of processing every input with the entire model, which would be very computationally expensive, MoE models activate only the most relevant experts for each token or task. This makes them significantly faster and more cost-effective
DeepSeekMoE is used for cost-effective training. DeepSeek-V3 uses finer-grained experts and isolates some experts as shared ones
It's designed to be both powerful and cost-effective, using advanced methods like Multi-head Latent Attention (MLA) and a new way to balance its workload without losing performance
This statement underscores the dual goal of DeepSeek-V3: high performance without exorbitant costs.
Multi-head Latent Attention (MLA) is a technique used for efficient inference. MLA reduces the Key-Value (KV) cache size during inference while maintaining performance, making the model faster and less memory-intensive. This is crucial for deploying the model for real-world applications.
MLA also reduces the activation memory during training through a low-rank compression
The "new way to balance its workload" refers to an auxiliary-loss-free load balancing strategy. Traditional methods for load balancing use an auxiliary loss which can sometimes negatively impact model performance. DeepSeek-V3 uses a method of adjusting a bias term for each expert to ensure that the work is divided effectively without compromising the model's ability to learn and perform
DeepSeek-V3 also employs a complementary sequence-wise balance loss to prevent extreme imbalance within any single sequence
Cool Features & How It Works:
Multi-Token Prediction: DeepSeek-V3 is trained to predict more than one word at a time, making it smarter and faster. This method helps it get better at understanding language
Efficient Training: The model uses FP8 mixed precision training, which means it can learn faster while using less memory. They also use something called DualPipe that lets the model do multiple things at once and speeds up training
Load Balancing: DeepSeek-V3 uses a new way of distributing the work between different experts in the model. This method is called auxiliary-loss-free load balancing, which makes sure that each part of the model is working effectively. This is important because it prevents any part of the model from doing too much work and slowing things down
Memory Saving: The training framework also optimizes memory usage, allowing the model to be trained without costly tensor parallelism
Long Context: DeepSeek-V3 is great at remembering and understanding long pieces of text, up to 128,000 tokens, which is a lot of words
Why Does It Matter?
Strong Performance: DeepSeek-V3 is one of the strongest open-source models available, especially in code and math
Cost-Effective: It's trained with less resources, meaning it's a good balance between power and cost. For example, it only took 2.788 million H800 GPU hours to train
Open-Source: Being open-source means that many people can use and improve it, which is great for everyone
Knowledge: DeepSeek-V3 excels in areas such as education, math and factuality. On educational benchmarks, its performance is comparable to leading closed-source models. In Chinese factual knowledge it surpasses models like GPT-4o and Claude-Sonnet-3.5
Reasoning: The model is also designed to distill reasoning capabilities from DeepSeek-R1, helping it perform better in areas requiring complex thinking
DeepSeek-V3 Outperforms:
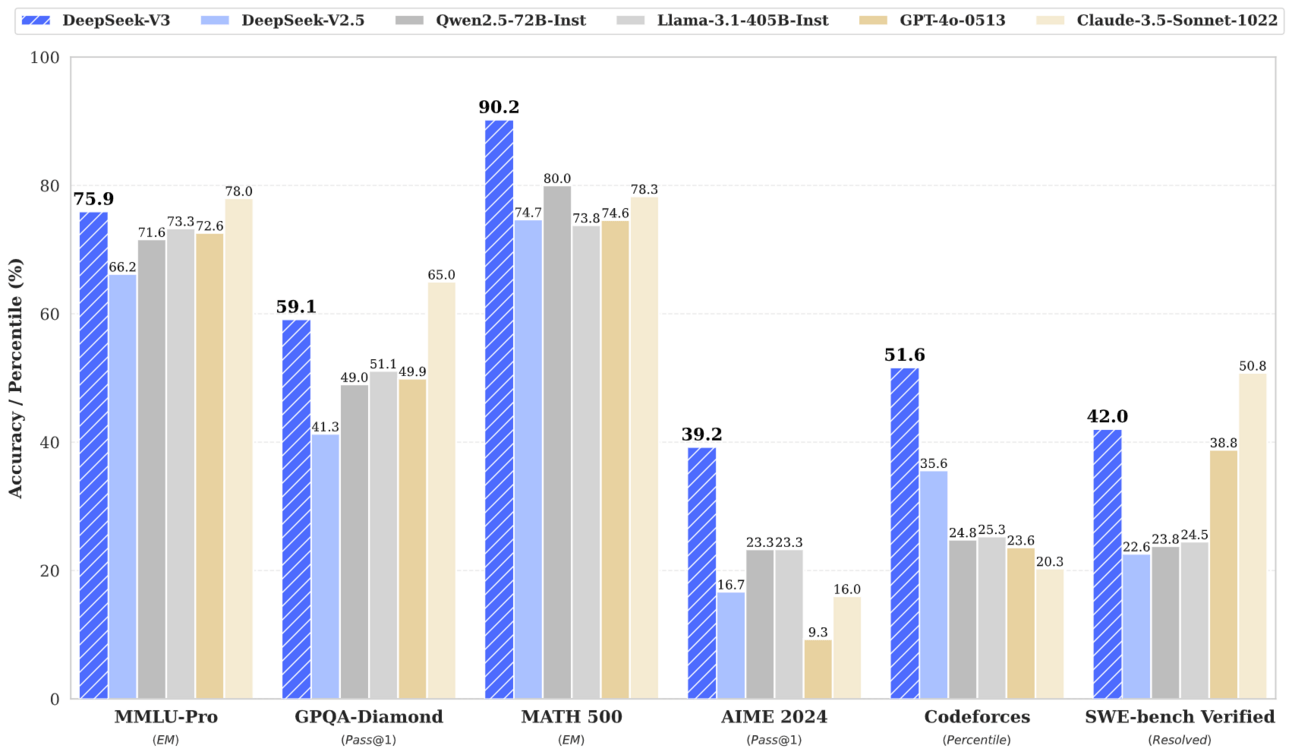
benchmark
The model's performance is measured against other models and it achieves excellent scores
MMLU-Pro: 75.9%
GPQA-Diamond: 59.1%
MATH 500: 90.2%
AIME 2024: 39.2%
Codeforces: 51.6 Percentile
SWE-bench Verified: 42.0%
DeepSeek-V3-Base achieves the best performance on most benchmarks, especially on math and code tasks
The chat version of DeepSeek-V3 also outperforms other open-source models and is comparable to top closed-source models such as GPT-4o and Claude-3.5-Sonnet
It surpasses other models in understanding long contexts and in algorithmic tasks and code generation
The top 6 bullet points represent the performance of DeepSeek-V3 on several different benchmarks designed to test various aspects of a language model's capabilities. Each benchmark focuses on a different area, from general knowledge to specialized skills like math and coding.
MMLU-Pro: 75.9% - MMLU-Pro stands for "Massive Multitask Language Understanding - Pro". It is a more challenging version of the MMLU benchmark, which tests a model's understanding across a wide range of academic subjects. The score of 75.9% means that DeepSeek-V3 answered 75.9% of the questions correctly on this benchmark. This demonstrates a high level of general knowledge and understanding. MMLU-Pro is a more robust and challenging multi-task language understanding benchmark.
GPQA-Diamond: 59.1% - GPQA-Diamond is a benchmark designed to test a model’s ability to answer questions at a graduate level. It requires a deep level of understanding and reasoning skills. The score of 59.1% indicates that DeepSeek-V3 successfully answered 59.1% of the questions on this very difficult benchmark. This shows the model has strong reasoning capabilities. DeepSeek-V3 ranks just behind Claude 3.5 Sonnet and outperforms all other competitors by a substantial margin on this benchmark.
MATH 500: 90.2% - MATH 500 is a subset of the MATH benchmark, which is designed to evaluate a model’s mathematical reasoning and problem-solving abilities. The score of 90.2% means that DeepSeek-V3 correctly solved 90.2% of the math problems in this benchmark, demonstrating a very high level of mathematical skill. DeepSeek-V3 achieves state-of-the-art performance on math-related benchmarks, outperforming even o1-preview on MATH-500.
AIME 2024: 39.2% - AIME 2024 refers to the American Invitational Mathematics Examination, a very challenging math competition for high school students. The score of 39.2% indicates that DeepSeek-V3 correctly answered 39.2% of the AIME math questions, which is a strong showing on a very difficult math test1. On the AIME benchmark, DeepSeek-V3 outperforms the second-best model, Qwen2.5 72B, by approximately 10% in absolute scores.
Codeforces: 51.6 Percentile - Codeforces is a platform for competitive programming, and this benchmark measures how well a model can solve coding problems under pressure. A percentile score of 51.6 means that DeepSeek-V3 performed better than 51.6% of the human competitors on the Codeforces platform. This shows a high level of coding skill and problem-solving ability.
SWE-bench Verified: 42.0% - SWE-bench Verified is a benchmark for evaluating a model's ability to solve software engineering problems. This benchmark has a human-validated subset of the SWE-bench. The score of 42.0% indicates that DeepSeek-V3 successfully resolved 42.0% of the problems in the SWE-bench verified benchmark. This shows a strong ability to handle practical software engineering tasks.
In Summary:
These numbers are not just random figures, they highlight specific strengths of DeepSeek-V3:
It has a strong grasp of general knowledge (MMLU-Pro).
It exhibits advanced reasoning abilities (GPQA-Diamond).
It demonstrates exceptional mathematical skills (MATH 500, AIME 2024).
It is very proficient in coding and algorithmic problem-solving (Codeforces, SWE-bench Verified).
These metrics demonstrate that DeepSeek-V3 is a very capable model across various domains and tasks, achieving impressive results that are comparable to or exceed other leading open-source and closed-source models. These scores provide a way to quantify the model's abilities and understand where its strengths lie.
Call to Action:
Want to learn more about DeepSeek-V3? You can find the model checkpoints and further details at their Technical Paper: DeepSeek-V31
Final Words
Thanks for joining me on this journey. More tips, projects, and updates are coming your way. Let’s build something great together! 🚀
See you next time,
Amit Mirgal

Reply